


IPFS - Content Addressed, Versioned, P2P File System
(DRAFT 3)
Juan Benet
요약
IPFS (InterPlanetary File System)는 모든 컴퓨팅 장치를 동일한 파일 시스템으로 연결하려는 피어 투 피어 분산 파일 시스템입니다. 어떤면에서는 IPFS웹과 유사하지만 IPFS는 하나의Git 내에서 객체를 교환하는 단일 BitTorrent 떼로 볼 수 있습니다.
저장소. 다시 말해, IPFS는 컨텐트 주소가 지정된 하이퍼 링크와 함께 높은 처리량의 컨텐트 주소가 있는 블록 스토리지 모델을 제공합니다. 이것은 일반화 된 머클을 형성합니다. 버전 화를 구축 할 수 있는 데이터 구조 인 DAG ,파일 시스템, 블록 체인 및 영구 웹까지.
IPFS 분산 해시 테이블, 인센티브 블록 교환 및 자체 인증 네임 스페이스를 결합합니다. IPFS에는 싱글이 없습니다
장애 지점 및 노드는 서로를 신뢰할 필요가 없습니다.
1. INTRODUCTION
글로벌 분산 파일 시스템을 구성하려는 많은 시도가 있었습니다. 어떤 시스템은 상당한 성공을 거두었고, 또 어떤 시스템은완전히 실패했다.
학술적 시도 중에서 AFS[6]는 널리 성공하여 오늘날에도 여전히 사용되고 있다.
다른 사람들은 [7, ?] 같은 성공을 거두지 못했다. 학계 밖에서가장 성공적인 시스템은 주로 대형 미디어(오디오 및 비디오)에 맞춘 피어 투 피어 파일 공유 애플리케이션이었다. 가장 주목할 만한 점은 냅스터, KaZaA, 비트토렌트[2]가 1억 명 이상의 동시 사용자를 지원하는 대형 파일 배포 시스템을 구축했다는 점이다.
오늘날에도 비트토렌트는 매일 수천만 개의 노드가 휘젓는 대규모 배치를 유지하고 있다[16].
이러한 애플리케이션은 학술 파일 시스템 상대보다 더 많은 수의 사용자와 파일이 배포되었다.
그러나 응용 프로그램은 인프라를 구축하도록 설계되지 않았다. 성공적인 용도 변경이 있었지만, 글로벌, 저 지연 및 분산 배포를 제공하는 일반적인 파일 시스템은 없었다.
아마도 이것은 대부분의 사용 사례에 대한 "충분히 좋은" 시스템이 이미 존재하기 때문일 것이다: HTTP.
지금까지 HTTP는 지금까지 배포된 것 중 가장 성공적인 "배포된 파일 시스템"이다. 브라우저와 결합하여 HTTP는 엄청난 기술적, 사회적 영향을 끼쳤다. 그것은 인터넷을 통해 파일을 전송하는 사실상의 방법이 되었다. 하지만, 그러나 지난 15 년간 발명 된 수십 가지의 뛰어난 파일 배포 기술의 이로운 점을 활용하지 못했다.
어떤 관점으로 보자면, 역호환성 제약의 수와 현재 모델에 이미 투자한 강력한 당사자들의 수를 고려할 때, 웹 인프라를 진화시키는 것은 거의 불가능에 가깝다.
예를 들어 리눅스 배포판은 디스크 이미지를 전송하기 위해 비트토렌트를 사용하고, 블리자드사는 이를 비디오 게임 콘텐츠를 배포하기 위해 사용한다.
그러나 또 다른 관점에서는 HTTP의 등장 이후 새로운 프로토콜이 등장하여 널리 이용되고 있다. 현재의 HTTP 웹을 향상시키고 사용자 경험을 저하시키지 않으면서 새로운 기능을 도입하는 설계 업그레이드라는 것이 부족하다.
업계는 트래픽이 많은 소규모 조직에서도 작은 파일을 옮기는것이 상대적으로 저렴하기 때문에 이렇게 오랫동안 HTTP를 사용하지 않고 있다. 그러나 우리는 다음과 같은 새로운 과제를 안고 새로운 데이터 배포 시대로 접어들고 있다.
(a)페타바이트 데이터셋의 저장 및 배포, (b) 컴퓨팅 조직 전체에 걸친 대용량 데이터, (c) 주문형 또는 실시간 미디
어 스트림, (d) 대규모 데이터셋의 버전 지정 및 링크, (e) 중요 파일의 우발적인 손실 방지 등 이들 중 많은 부분을 "많은 데이터, 어디서나 접근 가능"으로 요약할 수 있다. 중요한 특징과 대역폭 문제로 인해 우리는 이미 다른 데이터 배포 프로토콜에 대해 HTTP를 포기했다. 다음 단계는 웹 자체의 일부로 만드는 것이다.
효율적인 데이터 배포와 직교하여 버전 제어 시스템은 중요한 데이터 협업 워크플로우를 개발하는데 성공했다.
분산 소스 코드 버전 제어 시스템인 Git는 분산 데이터 운영을 모델링하고 구현하는 많은 유용한 방법을 개발했다.
Git 툴체인은 대형 파일 배포 시스템이 심각하게 결여된 다용도 버전 기능을 제공한다. 개인용 파일 스토리지 시스템인 Camlistore[?]와 Dat[?] 데이터 협업 툴체인 및 데이터셋 패키지 매니저와 같이 Git에서 영감을 받은 새로운 솔루션이 등장하고 있다. Git은 이미 Merkle DAG 데이터 모델을 통해 강력한 파일 배포 전략을 가능하게 함으로써 분산 파일 시스템 설계[9]에 영향을 미쳤다.
이 데이터 구조가 고처리 지향 파일 시스템 설계에 어떤 영향을 미칠 수 있는지, 그리고 어떻게 웹 자체를 업그레이드할 수 있는지에 대해 알아봐야 한다.
이 논문은 이러한 문제들을 조정하고자 하는 새로운 P2P 버전 제어 파일 시스템인 IPFS를 소개한다.
IPFS는 많은 과거의 성공적인 시스템으로부터 얻은 학습을 종합한다.
신중한 인터페이스 중심 통합은 그 부분의 합보다 더 큰 시스템을 산출한다.
중심 IPFS 원칙은 모든 데이터를 동일한 Merkle DAG의 일부로 모델링하는 것이다.
2. BACKGROUND
This section reviews important properties of successful peer-to-peer systems, which IPFS combines.
2.1 Distributed Hash Tables
Peer-to-peer 시스템에 대한 메타데이터를 조정하고 유지하기 위해 DHT(분산 해시 테이블)가 널리 사용된다.
예를 들어, BitTorrent 메인라인DHT는 급류 떼의 일부인 동료 들을 추적한다.
2.1.1 카뎀리아 DHT
Kademlia [10]은 다음과 같은 기능을 제공하는 인기 있는 DHT이다.
1. 대규모 네트워크를 통한 효율적인 조회: 평균 연락처[log2(n)]노드에 대한 쿼리 (예: 1,000,000개 노드의 네트워크
에 대해 20 hops).
2. 낮은 조정 오버헤드: 다른 노드로 보내는 제어 메시지의 수를 최적화한다.
3. 수명이 긴 노드를 선호하여 다양한 공격에 대한 저항.
4. Gnutella와 BitTorrent를 포함한 피어 투 피어 애플리케이션의 광범위한 사용으로 2,000만 개 이상의 노드로 네트워크를 형성한다[16].
2.1.2 산호 DSHT
일부 피어 투 피어 파일 시스템은 데이터 블록을 DHT에 직접 저장하지만, 이것은 "데이터는 필요하지 않은 노드에 저장되어야 하므로 스토리지와 대역폭을 낭비한다"[5].
Coral DSHT는 특히 중요한 세 가지 방법으로 Kademlia를 확장한다.
1. Kademlia는 ID가 "가장 가까운" 노드에 값을 저장한다. (using XOR-distance) 키에 연결. 이는 애플리케이션 데이터 인접성을 고려하지 않으며, 이미 데이터를 가지고 있을 수 있는 “far”노드를 무시하고, 필요하든 말든 "가장 가까운" 노드가 이를 저장하도록 강제한다.
이것은 상당한 저장과 밴드를 낭비한다. 대신 Coral은 데이터블록을 제공할 수 있는 피어에게 주소를 저장한다.
2. 코랄은 DHT API를 get_value(키)에서 get_any_values(키)로 이완시킨다(DSHT의 "sloppy").
코랄 사용자들은 전체 목록이 아니라 하나의 (작동하는) 피어만 필요하기 때문에 이것은 여전히 효과가 있다. 그 대가로 코랄은 핫스팟(키 인기 있을 때 가장 가까운 모든 노드 오버로드)을 피하면서 값의 하위 집합만 "가장 가까운" 노드에 배포할 수 있다.
3. 덧붙여 코랄은 지역과 크기에 따라 클러스터라고 불리는 별도의 DSHT의 계층을 구성한다.
이를 통해 노드는 해당 지역의 피어를 먼저 쿼리하고, "원거리노드 쿼리 없이 인근 데이터 찾기"[5]를 수행할 수 있으며, 검색 대기 시간을 크게 단축할 수 있다.
2.1.3 S/Kademlia DHT
S/Kademlia[1]는 다음과 같은 두 가지 특별히 중요한 방법으로 악의적인 공격으로부터 보호하기 위해 Kademlia를 확장한다.
1. S/Kademlia는 Node Id 생성을 확보하고 Sybill 공격을 방지하기 위한 계획을 제공한다. 노드가 PKI 키 쌍을 만들고, 그것에서 자신의 정체성을 도출하고, 서로 메시지를 서명하도록 요구하는 사항이다. 한 가지 계획은 작업증명서 암호화 퍼즐을 포함하고 있어 Sybills 생성을 비싸게 만든다.
2. S/Kademlia 노드는 네트워크에서 많은 수의 적수가 있는 상태에서 정직한 노드가 서로 연결할 수 있도록 하기 위해 분리 경로를 통해 값을 조회한다.
S/Kademlia는 노드의 절반만큼 큰 역적분율에서도 0.85의 성공률을 달성한다.
2.2 블록 교환 - 비트토렌트
비트토렌트[3]는 널리 성공한 피어 투 피어 파일 공유 시스템으로, 신뢰할 수 없는 피어(스왑)의 네트워크를 조정하여 파일조각을 서로 배포하는 데 협력하는 데 성공한다. 비트토렌트의 주요 특징과 IPFS 설계를 제공하는 그것의 생태계는 다음과 같다.
1. BitTorrent의 데이터 교환 프로토콜은 서로에게 기여하는 노드에 대해 보상을 하고, 다른 사람의 자원에만 기생하는 노드에 대해서는 처벌하는 즉, titfort-tat 전략을 사용한다.
2. BitTorrent 피어는 가장 희귀한 파일을 먼저 보내는 우선 순위를 지정하여 파일 조각의 가용성을 추적한다. 이것은 씨앗을 제거하여, 씨앗이 아닌 또래들이 서로 거래할 수 있게 한다.
3. 비트토렌트의 표준 팃포탯은 어떤 착취적 대역폭 공유 전략에 취약하다. PropShare [8]은 다른 피어 대역폭 할당 전략으로, 착취적 전략을 보다 효과적으로 억제하고 군집 성능을 향상시킨다.
2.3 버전 제어 시스템 - Git
버전 제어 시스템은 시간이 지남에 따라 변화하는 파일을 모델링하고 다른 버전을 효율적으로 배포할 수 있는 기능을 제공한다.
인기 있는 버전 제어 시스템 Git은 파일 시스템 트리의 변경사항을 분산 친화적인 방식으로 캡처하는 강력한 Merkle DAG 객체 모델을 제공한다.
1. 불변의 객체는 파일(blob), 디렉토리를 나타낸다. (트리) 및 변경 사항(커밋).
2. 오브젝트는 콘텐츠의 암호 해시에 의해 콘텐츠가 부가된다.
3. 다른 사물에 대한 링크가 내장되어 머클 DAG을 형성한다.
이것은 많은 유용한 무결성 및 워크플로우 속성을 제공한다.
4. 대부분의 버전 관리 메타데이터(브랜치, 태그 등)는 단순히 포인터 참조를 사용하여 만들고 업데이트하는 데 비용
이 적게 든다.
5. 버전 변경은 참조만 업데이트하거나 객체를 추가한다.
6. 버전 변경사항을 다른 사용자에게 배포하는 것은 단순히 객체를 전송하고 원격 레퍼런스를 업데이트하는 것이다.
2.4 자체 인증 파일 시스템 - SFS
SFS [12, 11]는 두 가지 모두에 대해 강력한 구현을 제안했다.
(a) 분산된 신뢰 체인과 (b) 평등주의자는 글로벌 네임스페이스를 공유한다.
SFS는 Self-Certified Filesystems를 구축하기 위한 기술을 도입했다:
다음의 scheme
/sfs/:
where Location is the server network address, and:
HostID = hash(public_key || Location)
따라서 SFS 파일 시스템의 이름은 서버를 인증한다.
사용자는 서버가 제공하는 공용 키를 확인할 수 있다.
기밀을 공유하여 모든 교통을 확보하다 모든 SFS 인스턴스는 이름 할당이 암호화된 글로벌 네임스페이스를 공유하며, 중앙집중화된 본체에 의해 게이트되지 않는다.
(2)Merkle Directed Acyclic Graph – Merkle Tree와 유사하지만 더 일반적인 구조. 데이터 중복 제거, 밸런싱할 필요가 없으며 리프 노드가 아닌 노드에는 데이터가 포함되어 있음
3. IPFS 설계
IPFS는 DHT, 비트토렌트, Git, SFS 등 이전의 피어투피어 시스템으로부터 성공적인 아이디어를 종합한 분산 파일 시스템이다.
IPFS의 기여는 입증된 기술을 그 부분의 합보다 더 큰 단일 응집성 시스템으로 단순화, 진화, 연결시키는 것이다.
IPFS는 애플리케이션 작성 및 배포를 위한 새로운 플랫폼과 대용량 데이터의 배포 및 버전을 위한 새로운 시스템을 제시한다.
IPFS는 심지어 웹 자체를 진화시킬 수도 있다.
IPFS는 피어투피어(peer-to-peer)로, 어떤 노드도 권한이 없다.
IPFS 노드는 IPFS 개체를 로컬 스토리지에 저장한다. 노드가 서로 연결되고 객체를 전송한다.
이러한 개체는 파일 및 기타 데이터 구조를 나타낸다.
IPFS 프로토콜은 다른 기능을 담당하는 하위 프로토콜 스택으로 나뉜다.
1. Identities - 노드 ID 생성 및 검증 관리 3.1절에 설명되어 있다.
2. Network - 다른 피어에 대한 연결을 관리하고 다양한 기본 네트워크 프로토콜을 사용한다. 구성 가능 (3.2절에 설명)
3. Routing - 특정 피어 및 개체를 찾기 위한 정보를 유지 관리한다. 로컬 및 원격 쿼리에 모두 응답.
기본값은 DHT이지만 스왑이 가능하다. 섹션 3.3에 설명되어 있다.
4. Exchange - 효율적인 블록 분배를 관리하는 새로운 블록 교환 프로토콜(BitSwap) 시장으로 모델링된 데이터 복제에 대한 인센티브는 약하다. Trade Strategies 교환 가능. 섹션 3.4에 설명되어 있다.
5. Objects - 링크가 있는 내용 추가 불변 객체의 Merkle DAG. 임의의 데이터 구조(예: 파일 계층 및 통신 시스템)를
나타내기 위해 사용된다. 섹션 3.5에 설명되어 있다.
6. Files - Git에서 영감을 받은 버전 파일 시스템 계층.
섹션 3.6에 설명되어 있다.
7.Naming - 자체 인증 변이 가능한 이름 시스템. 섹션 3.7에 설명되어 있다.
이러한 서브시스템은 독립적이지 않다; 그것들은 통합되고 혼합된 속성을 이용한다. 단, 프로토콜 스택을 아래에서 위로 쌓아서 따로 기술하는 것이 유용하다.
표기법: 아래의 데이터 구조와 함수는 Go 구문에 명시되어 있다.
3.1 신원 Identities
노드는 S/Kademlia의 정적 암호 퍼즐[1]로 생성된 공개키의 암호 해시3인 NodeId로 식별된다. 노드는 공용 키와 개인 키를 저장한다(암호로 암호화됨). 사용자들은 발생된 네트워크 효익은 상실하지만, 모든 출시 시 "새로운" 노드 아이덴티티를 자유롭게 주입할 수 있다. 노드는 동일하게 유지되도록 장려된다.
type NodeId Multihash
type Multihash [ ]byte
// self-describing cryptographic hash digest
type PrivateKey []byte
type PrivateKey []byte
// self-describing keys
type Node struct {
NodeId NodeID
PubKey PublicKey
PriKey PrivateKey
}
S/Kademlia based IPFS identity generation:
difficulty =
n = Node{}
do {
n.PubKey, n.PrivKey = PKI.genKeyPair()
n.NodeId = hash(n.PubKey)
p = count_preceding_zero_bits(hash(n.NodeId))
} while (p < difficulty)
Upon first connecting, peers exchange public keys, and check: hash(other.PublicKey) equals other.NodeId. If
not, the connection is terminated.
Note on Cryptographic Functions.
시스템을 특정 기능 선택 세트로 고정하기 보다는 IPFS는 자기 설명 값을 선호한다. 해시 다이제스트 값은 다중 해시 형식으로 저장되며, 여기에는 사용된 해시함수와 다이제스트 길이를 바이트 단위로 지정하는 짧은 헤더가 포함된다. Example:
이를 통해 시스템은 (a) 사용 사례에 가장 적합한 기능(예: 보안 강화 vs 빠른 성능)을 선택할 수 있으며, (b) 기능 선택이 변화함에 따라 진화한다. 자가 설명 값을 통해 서로 다른 매개 변수 선택 가능
3.2 Network
IPFS 노드는 잠재적으로 광역 인터넷을 통해 네트워크에 있는 수백 개의 다른 노드와 통신합니다.
The IPFS network stack features:
●Transport: IPFS는 모든 전송 프로토콜을 사용할 수 있으며 WebRTC DataChannels [?] (브라우저 연결 용) 또는 uTP(LEDBAT [14])에 가장 적합합니다.
●Reliability: 기본 네트워크가 uTP (LEDBAT [14]) 또는 SCTP [15]를 사용하여 제공하지 않는 경우 IPFS는 안정성을 제공 할 수 있습니다.
●Connectivity: IPFS also uses the ICE NAT traversal techniques [13].
●Integrity: 선택적으로 해시 체크섬을 사용하여 메시지의 무결성을 검사합니다.
●Authenticity: 발신자의 공개 키와 함께 HMAC를 사용하여 메시지의 진위 여부를 선택적으로 검사합니다.
3.2.1 Note on Peer Addressing
IPFS는 모든 네트워크를 사용할 수 있습니다. IP에 의존하거나 IP에 액세스한다고 가정하지 않습니다.
이를 통해 오버레이 네트워크에서 IPFS를 사용할 수 있습니다.
IPFS는 기본 네트워크에서 사용할 주소를 다중 주소 형식의 바이트 문자열로 저장합니다. multiaddr은 캡슐화 지원을 포함하여 주소와 프로토콜을 표현하는 방법을 제공합니다. For example:
# an SCTP/IPv4 connection
/ip4/10.20.30.40/sctp/1234/
# an SCTP/IPv4 connection proxied over TCP/IPv4
/ip4/5.6.7.8/tcp/5678/ip4/1.2.3.4/sctp/1234/
3.3 Routing
IPFS 노드에는 (a) 다른 피어의 네트워크 주소 및 (b) 특정 개체를 제공 할 수있는 피어를 찾을 수있는 라우팅 시스템이 필요합니다.
IPFS는 2.1에서 논의 된 특성을 사용하여 S / Kademlia 및 Coral 기반 DSHT를 사용하여이를 달성합니다.
IPFS의 개체 크기와 사용 패턴은 Coral [5] 및 Mainline [16]과 유사하므로 IPFS DHT는 크기에 따라 저장된 값을 구별합니다. 작은 값 (1KB 이하)은 DHT에 직접 저장됩니다.
더 큰 값의 경우 DHT는 블록을 제공 할 수 있는 피어의 NodeId 인 참조를 저장합니다.
The interface of this DSHT is the following:
type IPFSRouting interface {
FindPeer(node NodeId)
// gets a particular peer’s network address
SetValue(key []bytes, value []bytes)
// stores a small metadata value in DHT
GetValue(key []bytes)
// retrieves small metadata value from DHT
ProvideValue(key Multihash)
// announces this node can serve a large value
FindValuePeers(key Multihash, min int)
// gets a number of peers serving a large value
}
Note:
다른 사용 사례는 실질적으로 다른 라우팅 시스템 (예 : 광역 네트워크의 DHT, 로컬 네트워크의 정적 HT)을 요구합니다. 따라서 IPFS 라우팅 시스템을 사용자의 요구에 맞는 시스템으로 교체 할 수 있습니다. 위의 인터페이스가 충족되는 한 나머지 시스템은 계속 작동합니다.
3.4 Block Exchange - BitSwap Protocol
IPFS에서 데이터 분배는 BitTorrent에서 영감을 얻은 프로토콜인 BitSwap을 사용하여 피어와 블록을 교환함으로써 이루어집니다.
BitTorrent와 마찬가지로 BitSwap 피어는 세트를 획득하려고 합니다.
블록 (want_list)과 교환 할 다른 블록 세트 (have_list)가 있습니다. BitTorrent와 달리 BitSwap은 하나의 토렌트에 있는 블록으로 제한되지 않습니다. BitSwap은 블록이 포함 된 파일에 관계없이 노드가 필요한 블록을 획득 할 수 있는 지속적인 마켓 플레이스로 작동합니다.
블록은 파일 시스템에서 완전히 관련이 없는 파일에서 올 수 있습니다. 시장에서 노드들이 서로 물물 교환하기 위해 모인다.
교환 시스템의 개념은 가상 통화가 생성 될 수 있음을 의미하지만, 통화의 소유권과 이전을 추적하려면 글로벌 원장이 필요합니다. 이것은 BitSwap 전략으로 구현 될 수 있으며 향후 논문에서 살펴볼 것입니다.
기본 경우, BitSwap 노드는 블록 형태로 서로에게 직접적인 가치를 제공해야합니다. 노드에 걸친 블록 분포가 상호 보완적일 때, 즉, 다른 노드가 원하는 것을 갖고 있을 때, 이것은 잘 작동합니다.
종종 그렇지 않습니다.
어떤 경우에는 노드가 블록에 대해 작동해야 합니다.
노드가 피어가 원하는 것 (또는 아무것도 아님)을 가지고 있지 않은 경우, 노드가 원하는 것보다 우선 순위가 낮은 피어가 원하는 조각을 찾습니다.
이는 노드가 직접 관심이없는 경우에도 노드를 캐시하고 배포하는 인센티브를 제공합니다.
3.4.1 BitSwap Credit
또한 프로토콜은 노드들이 특별히 어떤 것을 필요치 않을 때, 다른 노드가 원하는 블록을 가질 수 있으므로 노드가 시드(씨를 뿌리도록)하도록 인센티브를 제공해야합니다.
따라서 BitSwap 노드는 블록을 피어들에게 부채가 상환 될 것으로 예상하며 낙관적으로 전송합니다.
그러나 거머리 (공유하지 않는 프리 로딩 노드)는 보호해야합니다.
간단한 신용 시스템으로 문제를 해결:
1. 피어는 다른 노드와의 균형 (확인 된 바이트)을 추적합니다.
2. Peers는 부채가 증가함에 따라 떨어지는 기능에 따라, 채무자 동료에게 확률 적으로 블록을 보냅니다.
노드가 피어에게 보내지 않기로 결정하면 노드는 이후 ignore_cooldown 시간 종료에 대한 피어를 무시합니다. 이것은 발신자가 더 많은 주사위 굴림을 일으켜서 게임을 할 수 없게합니다. 기본 BitSwap은 10 초입니다.
3.4.2 BitSwap Strategy
BitSwap 피어가 사용할 수있는 다양한 전략 교환의 성과에 전체적으로 큰 영향을 미칩니다.
BitTorrent에서는 표준 전략이 지정되어 있지만 (Tat-for-Tat) BitTyrant [8] (최소한 가능성 공유)부터 BitThief [8] (취약점 탐색 및 공유하지 않음)에 이르기까지 다양한 전략이 구현되었습니다. PropShare [8] (비례 공유)에. BitSwap 피어는 다양한 전략 (양호 및 악의)을 유사하게 구현할 수 있습니다.
그런 다음 기능의 선택 목표로 해야합니다:
1. 노드의 거래 성과를 극대화하고 전체 교환
2. 프리 로더가 익스체인지를 악용하고 저하시키지 못하도록 방지
3. 다른 알려지지 않은 전략에 효과적이며 저항함
4. 신뢰할 수 있는 동료에게 관대하다
그러한 전략의 공간을 탐구하는 것은 미래의 일이다.
실제로 작동하는 기능 중 하나는 부채 비율에 따라 조정되는 S자형입니다:
Let the debt ratio r between a node and its peer be:
r = bytes_sent / bytes_recv + 1
Given r, let the probability of sending to a debtor be:
P(send | r) = 1 − 1 / 1 + exp(6 − 3r)
그림 1에서 볼 수 있듯이이 기능은 노드의 부채 비율이 기존 신용의 두 배를 초과함에 따라 빠르게 사라집니다.
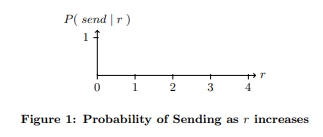
부채비율은 신뢰의 척도로, 이전에 많은 데이터를 성공적으로 교환한 노드 간의 부채에 관대하고, 알려지지 않은 신뢰할 수 없는 노드에는 무자비하다. 이 (a)는 많은 새로운 노드(증거금 공격)를 창출할 공격자에게 저항을 제공하고, (b) 노드 중 하나가 일시적으로 가치를 제공할 수 없는 경우에도 이전에 성공한 거래 관계를 보호하며, (c) 결국 개선될 때까지 악화된 관계를 격화시킨다.
3.4.3 BitSwap Ledger
BitSwap 노드들은 다른 노드들과 전송을 계속 회계처리한다. 이것은 노드가 역사를 추적하고 변조하는 것을 피할 수 있게 해준다. 연결을 활성화할 때 BitSwap 노드는 자신의 원장 정보를 교환한다. 정확하게 일치하지 않으면 원장을 처음부터 다시 초기화하여 미지급된 신용이나 부채를 잃게 된다. 악성 노드가 부채를 지우기를 바라며 의도적으로 레저를 '지울' 수 있다. 노드들이 누적된 신뢰도 상실할 만큼 충분한 부채가 발생하지는 않을 것이다. 그러나 파트너 노드는 이를 위법행위로 간주할 수 있고 거래를 거부할 수 있다.
type Ledger struct {
owner NodeId
partner NodeId
bytes_sent int
bytes_recv int
timestamp Timestamp
}
정확한 운용에 필요한 것은 아니지만, 노드는 자유롭게 원장기록을 보관할 수 있다. 현재 원장 기재사항만 유용하다. 노드는 또한 필요 시 가비지 수집용 레져를 무료로 수집할 수 있으며, 보다 유용하지 않은 레저부터 시작한다: the old (peers may not exist anymore) and small.
3.4.4 BitSwap Specification
BitSwap nodes follow a simple protocol.
// Additional state kept
type BitSwap struct {
ledgers map[NodeId]Ledger
// Ledgers known to this node, inc inactive
active map[NodeId]Peer
// currently open connections to other nodes
need_list []Multihash
// checksums of blocks this node needs
have_list []Multihash
// checksums of blocks this node has
}
type Peer struct {
nodeid NodeId
ledger Ledger
// Ledger between the node and this peer
last_seen Timestamp
// timestamp of last received message
want_list []Multihash
// checksums of all blocks wanted by peer
// includes blocks wanted by peer’s peers
}
// Protocol interface:
interface Peer {
open (nodeid :NodeId, ledger :Ledger);
send_want_list (want_list :WantList);
send_block (block :Block) -> (complete :Bool);
close (final :Bool);
}
Sketch of the lifetime of a peer connection:
1. Open: peers send ledgers until they agree.
2. Sending: peers exchange want_lists and blocks.
3. Close: peers deactivate a connection.
4. Ignored: (special) a peer is ignored (for the duration of a timeout) if a node’s strategy avoids sending Peer.open(NodeId, Ledger).
Peer.open(Nodeld, Ledger)
연결 시, 노드는 과거의 연결에서 저장되거나 영점 처리된 새로운 연결에서 Ledger와의 연결을 초기화한다. 그런 다음, 피어에게 Ledger와 함께 Open 메시지를 전송한다.
열린 메시지를 수신하면 피어가 연결을 활성화할지 여부를 선택한다. 수취인의 대장에 기재한 경우, 발신인이 신뢰할 수 있는 대리인이 아닌 경우(0 이하의 송금 또는 거액의 미지불채무) 수령자는 요청을 무시하기로 선택할 수 있다. 이 작업은 ignore_cooldown 시간 초과로 확률적으로 수행되어야 하며, 오류를 수정하고 공격자를 좌절시킬 수 있어야 한다.
연결을 활성화하는 경우, 수신기는 로컬 버전의 레져로 피어 객체를 초기화하여 마지막으로 볼 수 있는 타임스탬프를 설정한다.
그런 다음, 수령한 레저를 자신의 것과 비교한다.
정확히 일치하면 연결이 열린 거야 만약 그들이 일치하지 않는다면, 피어는 영점 처리된 새로운 레저를 만들어 그것을 보낸다.
Peer.send_want_list(WantList).
연결이 열려 있는 동안 노드는 연결된 모든 피어에 자신의 want_list를 알린다. 이 작업은 (a) 연결을 열 때, (b) 임의 주기 제한 시간 이후, (c) want_list 변경 후, (d) 새로운 블록을 받은 후 수행된다.
want_list를 받으면 노드가 이를 저장한다. 그런 다음, 원하는 블록이 있는지 확인한다. 그렇다면 위의 BitSwap 전략에 따라 전송한다.
Peer.send_block(Block).
블록을 보내는 것은 간단하다. 그 노드는 단순히 데이터 블록을 전송한다. 모든 데이터를 수신하는 즉시, 수신자는 멀티해시 체크섬을 계산하여 그것이 예상한 것과 일치하는지 확인하고, 확인을 반환한다.
블록의 정확한 전송을 완료한 후, 수신자는 need_list에서 have_list로 블록을 이동시키고, 수신자와 송신자 모두 전송된 추가 바이트를 반영하기 위해 그들의 레저를 업데이트한다.
송신 검증에 실패하면 송신자가 오작동하거나 수신기를 공격하고 있다. 그 수취인은 자유롭게 더 이상의 거래를 거절할 수있다. BitSwap은 신뢰할 수 있는 전송 채널에서 작동할 것으로 예상하므로, 전송 오류(정직한 송신자의 잘못된 처벌로 이어질 수 있음)는 데이터가 BitSwap에 전달되기 전에 포착될 것으로 예상된다.
Peer.close(Final).
연결을 끊기 위한 최종 매개변수는 연결을 해체하려는 의도가 송신자의 것인지 여부를 신호한다.
만일 거짓이면, 수신기가 즉시 연결을 다시 여는 것을 선택할 수 있다. 이렇게 하면 조기 폐쇄를 피할 수 있다.
피어 연결은 다음 두 가지 조건에서 닫아야 한다:
●peer로부터 메시지를 수신하지 않고 silence_wait 시간 초과가 만료됨(기본 BitSwap은 30초 사용). 노드가 Peer.close(거짓)를 발급한다.
●노드가 종료되고 BitSwap이 종료되는 중. 이 경우 노드는 Peer.close(true)를 발행한다.
메시지를 닫은 후 수신자와 발신자 모두 연결을 해체하여 저장된 상태를 지운다. 만약 그렇게 하는 것이 유용하다면, 레저는 미래를 위해 보관될 수 있다.
Notes.
비활성 연결에서 열려 있지 않은 메시지는 무시해야 한다. send_block 메시지의 경우, 수신자는 블록이 필요한지 확인하고, 필요한지 확인하여 수정하고, 필요한 경우 사용할 수 있다. 그럼에도 불구하고, 그러한 모든 주문되지 않은 메시지는 수신기에서 닫힌(거짓) 메시지를 트리거하여 연결의 재초기화를 강제한다.
3.5 Object Merkle DAG
DHT와 비트스왑은 IPFS가 블록을 빠르고 강력하게 저장 및 배포하기 위한 대규모 "피어 투 피어" 시스템을 구성할 수 있도록 한다. 그 위에 IPFS는 물체들 사이의 링크가 소스에 내장된 대상들의 암호 해시인 다이렉티드 Acyclic 그래프인 Merkle DAG를 구축한다. 이것은 Git 데이터 구조를 일반화한 것이다. Merkle DAG는
IPFS에 많은 유용한 속성을 제공한다:
1. 내용 주소 지정: 모든 콘텐츠는 링크가 포함된 다중 해시 체크섬으로 고유하게 식별된다.
2. 변조 저항: 모든 콘텐츠는 체크섬으로 검증된다. 데이터가 변조되거나 손상된 경우 IPFS가 이를 탐지한다.
3. 데이터 중복 제거: 동일한 컨텐츠를 보유하고 있는 모든 개체는 동일하며, 한 번만 저장된다. 이것은 특히 git 트리와 커밋 또는 데이터의 공통 부분과 같은 인덱스 객체에 유용하다.
The IPFS Object format is:
type IPFSLink struct {
Name string
// name or alias of this link
Hash Multihash
// cryptographic hash of target
Size int
// total size of target
}
type IPFSObject struct {
links []IPFSLink
// array of links
data []byte
// opaque content data
}
IPFS Merkle DAG는 데이터를 저장하는 매우 유연한 방법이다. 유일한 요구사항은 객체 참조가 (a) 주소의 내용이고 (b) 위의 형식으로 인코딩되는 것이다. IPFS는 애플리케이션에게 데이터 필드에 대한 완전한 제어를 부여하고, 애플리케이션은 IPFS가 이해하지 못할 수 있는 어떤 사용자 정의 데이터 형식도 사용할 수 있다. 별도의 inobject 링크 테이블은 IPFS에서:
● 객체의 모든 객체 참조를 나열한다. For example:
> ipfs ls /XLZ1625Jjn7SubMDgEyeaynFuR84ginqvzb
XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x 189458 less
XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5 19441 script
XLF4hwVHsVuZ78FZK6fozf8Jj9WEURMbCX4 5286template

더욱 다양한 정보 및 방송 관련 소식은
공식 SNS 채널을 통해 확인 가능합니다.





좋은 소식 감사합니다,^^